4 Powerful Long Text Summarization Methods With Real Examples
Text summarization is an NLP process that focuses on reducing the amount of text from a given input while at the same time preserving key information and contextual meaning. With the amount of time and resources required for manual summarization, it's no surprise that automatic summarization with NLP has grown across a number of different use cases for many different document lengths. The summarization space has grown rapidly with a new focus on handling super large text inputs to summarize down into a few lines. The increased demand for the summarization of longer documents such as news articles and research papers has driven the growth in the space.
The key changes that have led to the new push in long text summarization are the introduction of transformer models such as BERT and GPT-3 that can handle much longer input sequences of text in a single run and a new understanding of chunking algorithms. Past architectures such as LSTMs or RNNs were not as efficient nor as accurate as these transformer based models, which made long document summarization much harder. The growth in understanding of how to build and use chunking algorithms that keep the structure of contextual information and reduce data variance at runtime has been key as well.
Difference Between Large & Small Text Summarization
Packing all the contextual information from a document into a short summary is much harder with long text. If our summary has to be say 5 sentences max it is much harder to decide what information is valuable enough to be added with 500 words vs 50,000 words.
Chunking algorithms are often required, but they do grow the data variance coverage a model must have to be accurate. Chunking algorithms control how much of the larger document we pass into a summarizer based on the max tokens the model allows and parameters we’ve set. The new dynamic nature of the input data means our data variance is much larger than what is seen with smaller text.
Longer documents often have much more internal data variance and swings in the information. Use causes such as blog posts, interviews, transcripts and more have multiple swings in the dialog that make it harder to understand what contextual information is valuable for the summary. Models have to learn a much deeper relationship between specific keywords, topics, and phrases as the text grows.
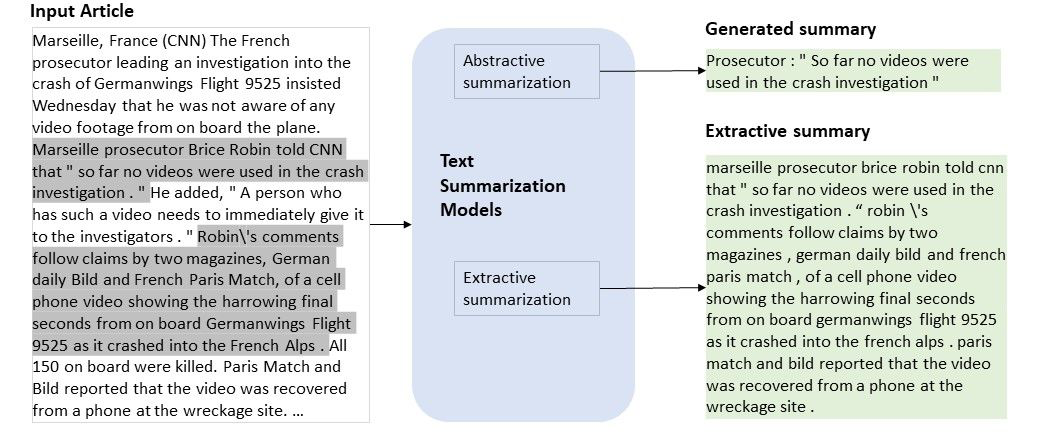
There are two main types of summarization that are used as the baseline for any enhanced versions of summarization - Extractive and abstractive. They focus on how the key information found in the input text is reconstructed in the generated summary in their own ways. Both of these methods have their own unique challenges that pop up when looking at using longer text.
4 Key Methods of Long Text Summarization
There are a number of different methods of summarizing long document text using various architectures and frameworks. We’ll look at some of the most popular ones used today and the various use cases that we have seen them perform exceptionally well for.
Long Text Summarization with GPT-4
The release of GPT-4 has changed two key aspects of long text summarization and has various pros and cons. Most customers immediately think that GPT-4 is the route to go right now no matter the use case or documents they want to process, but there are a number of things you want to consider before making this switch. Let’s talk about the key aspects GPT-4 has changed:
Chunking
Its no secret that GPT-4 has a larger prompt size then GPT-3 and many other models. This in theory means that we don’t need to chunk the document into as many text blocks as previously needed. While this is true, there are a number of different things to consider using this extra space for outside of just having less chunks, as in my experience less chunks does not affect summarization as much as customers believe it will, and these additional tokens can be used for other more valuable prompt operations.
Further understanding of instructions
GPT-4 has improved quite a bit at following more complex instructions or multi-step instructions. Instructions no longer have to be provided in a simpler structure and things like Chain of Thought and Tree of Thoughts have expanded this even further. We now use much more complex instructions even before getting to prompt examples.
GPT-4 long text summarization comes with a number of pros and cons compared to what was being done at a production level with GPT-3. We’ll see these throughout the examples below, but its critical to outline them to always have them in mind when developing these systems.
Pro: Reduction of chunks required
Given the increase in prompt size one of the immediate pros that customers think of is the need for less chunking of the document to reach a final summary. The pipeline at a high level looks like this:
Full document -> chunk of the document -> summary of that chunk -> combine all chunk summaries into one full document summary.
The key problem usually seen with this workflow is that combining these chunk summaries can cause us to lose important information, duplicate information, and simply produce a final summary that becomes larger or smaller based on the number of chunks, not the actual information in the document. The solution that customers come to is “less chunks, better summary” given we can reduce instances where those above outcomes occur. While this is partially true, the solution is not to go from 10 chunks to 5. It's better to use this extra prompt space for prompt examples, more complex instructions, and new variables, and reduce to 7 or 8 chunks. This gives our prompt more clarity around the chunk that is provided which will help more with reduction of duplicate information and information understanding, while still reducing the size of the output summary.
Con: No access to log probabilities
Log probabilities tell us the probability of a given token to appear in a sequence. This information is incredibly valuable as it tells us what word or token the model was most “confident” in. While the other tokens that were options are not incorrect or not viable options, they were not as likely to be used in this specific spot as other words.
Log probabilities for the above paragraph when put in GPT-3. The model actually likes the word “token” better than what I chose.
Log probabilities are a great tool for optimizing prompts, evaluating results, improving generations, and many more tasks that are key when using sequence models. We use them all the time for these same operations, as it lets us get into the mind of GPT and understand what it thinks about an output.
Log probabilities are not accessible on GPT-4. OpenAi has not made them available for viewing or the color coding you see above. This removes any of the above operations from our toolbox for improving prompts and iterating forward. It also makes the temperature parameter a bit less useful during testing, as we don’t know which surface level tokens are lower probability vs the others. This keeps us from doing a ton of testing with higher temperatures and fully understanding the output options for a given prompt.
Pro: Better understanding of complex and long prompts
One of the key ideas behind why you use instruction style prompts is that you can steer the model towards what you define as your goal state output, vs what the model, a user, or a different engineer believes it is. For our use case this just means we can use the prompt to help the model better understand what information to include in our summary, what format we want it in, extractive vs abstractive etc. If we were to provide a prompt such as “summary this document” our model doesn’t have much information around what would be a good output for us, and will rely on its idea of what a good output is. The flip to this would be if we provide a prompt such as “Extract exact key information from the provided text in 5 sentences that focuses on xyz”. You can see how we’ve provided a much deeper idea to the model of what a good output is for us (goal state output).
GPT-4 is much better than GPT-3 at understanding more complex prompt instructions in zero-shot scenarios, or scenarios where we don’t provide exact input and output examples of the summaries of example documents. We’ll see in examples below that the prompts we can provide can be much more complex, contain multiple steps, have clear guidelines, and much more that GPT-3 simply struggles with. The model is also very good at understanding the idea of pretending to be certain roles, such as a creative writer, an engineer, a student etc. This role play idea is something that we initially weren’t too keen on, as the value add didn’t make much sense over better prompts or prompt examples. Through testing and even integrating it into production we’ve found this role play idea very useful for less experienced prompt engineers or giving the model a more generalized idea of what output goal state we want to steer towards.
Con: GPT-4s reluctance to follow prompt examples
Similar to what we just discussed above, the goal of prompt examples is to provide the model with an idea of what our goal state output is for a given use case, and to have the model strongly follow a specific format. This is normally called “few-shot” learning.
GPT-3 does a great job of strongly following the examples and picking up on the idea that in most cases, we don’t want the model to explore other formats, language sequences, and lengths. GPT-3 is trained in large part to do this, partially because of its size compared to GPT-4, and the value put on instructions in the prompt.
GPT-4 doesn’t always want to follow the queues laid out in prompt examples as much, and tends to wander away from the key ideas outlined. While prompt instructions can be used to clean this up, it limits the dynamic nature of our prompts and the way we can outline different prompts based on the different inputs provided.
Blog Summarization Example
Let’s take a look at a comparison of GPT-4 and GPT-3 for different summarization use cases. We’re going to focus on summarizing this opinion summarization blog post we wrote. We used a chunk of around 2300 tokens to give both models an equal comparison in the same environment (zero-shot vs few-shot etc).
The GPT-4 summary seems to focus a bit more on actual terms and models used in the blog post, and understands that with the limited amount of space (3 sentences) it should mention those ideas. The GPT-3 one mentions the idea of extractors, but doesn’t name any of them. The last sentence in the GPT-3 summary doesn’t blend well with the rest of the summary and almost reads in an extractive nature with how it doesn’t relate to any of the above. Most reviewers would dock this summary for that reason. On the other hand, GPT-4 summary does waste a bit of the sentence by saying “the post also highlights” instead of using a bit briefer language. This use of exact terms and models will be critical when combining all the chunk summaries as key context will be lost without very in-depth information in the chunk summaries.
Here’s a summary of the same text with more instructions and outline of what the goal state output should look like:
With this added context around what information we want to include in our summary we see that GPT-3 improves and now discusses more in-depth information. The GPT-4 summary stays mostly the same, with the first sentence improving a bit to mention extractors and summarizers, which leaves us room to discuss other things in the next sentence.
News Summarization Example
Example news article summary from our blog post on news article summarization. Great example of zero-shot word count restricted summarization with GPT-4.
News articles have a similar structure to the above blog posts or other long form information based readings. They are also often single entity focused which makes summarization of the entire text much easier as the context does not switch as dramatically and most chunk topics center around one high level idea. I recommend reading our entire article on this topic that shows key comparisons to other methods, aspect-based summarization prompts, and a new era of evaluation metrics that help improve these GPT summaries.
Long Text Extractive Summarization with BERTSUM
Extractive summarization works to extract near exact phrases or key sentences from a given text. The processing pipeline is similar to that of a binary classification model that acts on each sentence.
BertSum is a fine-tuned BERT model with a focus on extractive summarization. BERT is used as the encoder in this new architecture and has state of the art ability in handling long inputs and word to word relationships. This pipeline is using BERT as a baseline and creating a domain specific fine-tuned model is pretty popular as leveraging the baseline training can provide a large accuracy boost in the new domain and requires fewer data points.
The key change when going from baseline to BertSum is how the input format changes. We are representing individual sentences instead of the entire text at a single time so we add a [CLS] token to the front of each sentence instead of the entire document. When we run through the encoder we use these [CLS] tokens to represent our sentences.
Pros & Cons of BertSum
A key pro of the BertSum architecture is the flexibility that comes with BERT in general. The size and speed of these models are often something that becomes part of the equation when looking at how to get through long input text. There are a number of variations of BertSum that use different baseline BERT models such as DistilBERT and MobileBERT which are much smaller and achieve nearly identical results.
Nearly Identical accuracy numbers yet much smaller (source)
Another pro generally seen with extractive summarization is the ease with which you can evaluate for accuracy. Given the near exact sentence nature of the summarized text, it’s much easier to compare to a ground truth dataset for accuracy than it is with abstractive summarization.
The main con we see with long text summarization using BertSum is the underlying token limit of BERT. BertSum has an input token limit of 512 which is much smaller than what we see today with GPT-3 (4000+ in the newest instruct version). This means for long text summarization we have to do a few special things:
1. Build chunking algorithms to split up the text.
2. Manage a new level of data variance considering each text chunk doesn’t contain all contextual information from above. 3. Manage combining chunk outputs at the end.
I won’t dive into the full level of depth on this point (considering I did it here: gpt-3 summarization), but the even lower token limit of BertSum can cause issues.
News Article Summarization With BertSum
We use BertSum to create a paragraph length summary of news articles that contain exact important sentences pulled from the longform text. BertSum lets us adjust the length of the summary that we want to use which directly affects what information from the article is deemed important enough to be included.
We’ve used the same exact existing models pipeline seen above to summarize any blog posts or guest posts of any size into a short and sweet summary. We took one of our longest articles with over 6k words and summarized it into a paragraph. We can always adjust the output length of the summary to better fit the amount of information or length of the blog post as well.
As we saw in the cons for BertSum, transformer based models struggle to handle super long input sequences due to their self-attention mechanism which scales quickly as the sequence length grows. The longformer works to fix this as it uses an attention mechanism that scales linearly with the sequence length as a local windowed attention and task motivated attention. This makes it much easier to process documents with thousands of tokens in a single instance. We use a variation of this called Longformer Encoder-Decoder for the summarization task.
The longformer architecture is set up in a similar way to how we use BERT in the modern age. The longformer is often used as a baseline language understanding model and then retrained or fine-tuned for various tasks such as summarization, QA, sequence classification, and many more. The architecture consistently outperforms BERT based models such as RoBERTa on long document tasks and has archived state of the art results in a few domains.
Given many of the struggles we discussed in the above sections that come with summarizing long text with any model it's pretty easy to see how the longformer encoder decoder benefits us. By extending the number of tokens we can use in a single run we can limit how many chunks of text we need to create. This greatly helps us hold the important context from the long document in place without splitting it into any group of chunks, which leads to stronger summaries at the end. The longformer also makes it much easier to combine all the smaller chunk summaries into one final summary as we have less to combine.
Longformer Summarization With 8k Tokens
Recently the longformer encoder-decoder architecture was fine-tuned for summarization on the very popular Pubmed summarization dataset. Pubmed is a large document dataset built for summarization of medical published papers. The median token length in the dataset is 2715 with 10% of the documents having 6101 tokens. With the longformer encoder-decoder architecture we will set the maximum length to 8192 tokens and can be done on a single GPU. In the most popular examples, we set the maximum summary length to 512 tokens.
Long Text Abstractive summarization with GPT-3
What is Abstractive Summarization?
Abstractive summarization focuses on generating a summary of the input text in a paraphrased format that takes all information into account. This is very different from what we see with extractive summarization as abstractive summarization does not generate a paragraph made up of each “exact best sentence”, but a concise summary of everything.
What is GPT-3?
GPT-3 is a transformer based model that was released by OpenAi in June of 2020. It is one of the largest transformer models to date with 175 billion parameters. The large language model architecture was trained on a very large amount of data including all of common crawl, all of Wikipedia, and a number of other large text sources. The model is autoregressive and uses a prompt based learning format which allows it to be tuned at runtime for various use cases across NLP.
GPT-3 For Long Text Abstractive Summarization
GPT-3 has a few key benefits that make it a great choice for long text summarization:
1. It can handle very long input sequences
2. The model naturally handles a large amount of data variance
3. You can blend extractive and abstractive summarization for your use case.
The last bullet is by far the biggest benefit of using GPT-3. Oftentimes summarization tasks are not strictly extractive or abstractive in the nature of what a completely correct output looks like. Some use cases such as this key topic extraction pipeline the summary is presented as bullets with some parts of exact phrases from the text, but mirror more of a 75/25 abstractive split. This ability to blend the two rigid ideas of summarization is an outcome of the extreme flexibility offered by the prompt based programming of GPT-3. The prompt based logic allows us to start generating these custom summaries without needing to find a pretrained model exactly like we need or creating a huge dataset.
Width.ai Zero Shot Summarizer Tool Pipeline
Get Started With Long Text Summarization
Width.ai is an NLP & CV development and consulting company focused on building powerful software solutions (like a text summarizing tool!) for amazing organizations. We help you through the entire process of outlining what you need for your use case, what models will produce the highest accuracy, and how we build exactly what you need. Speak to a consultant today to start outlining your own long text summarization product.