The Best Scraping API for Amazon Product Data using Smarter Ai Agents
The best scraping APIs for Amazon product data return structured JSON, not raw HTML. See how Pumice does it.

Matt Payne
July 7, 2026
Product attribute enrichment is the process of taking raw product data (titles, sparse supplier descriptions, basic SKU records) and turning it into a structured catalog where every product carries the detailed product attributes shoppers actually search and filter on. These are core attributes that describe the product like color, size, material, dimensions, fabric type, and contextual attributes like party wear, beach-friendly, winter essential, dewy finish, eco-friendly.
This guide breaks down what product attribute enrichment is and why it is the highest-priority catalog lever for boosting conversions, search discoverability, and AI shopping visibility. We cover the core and contextual attributes the process produces, the specific challenges it solves across PIMs, multi-vendor catalogs, and B2B environments, and how enriched attributes activate downstream across faceted search, product schema, marketplaces, and ad platforms. We close with a walkthrough of how to automate the entire process through the Pumice merchandising pipeline using our attribute endpoints.
Product attribute enrichment is the process of filling in the structured product attributes or specifications a PDP needs, but a supplier feed/vendor flat file almost never delivers. A data entry team takes the sparse, inconsistent data that arrives from manufacturers, vendors, ERPs, and PIMs (a title, a category, maybe a basic spec or two) and turns it into a complete catalog where every SKU is described in the same vocabulary, with the same attribute fields populated, across every channel the brand sells through.

The output is key/value pairs broken into two attribute types that shoppers actually search and filter on - core specs and contextual specs. Most legacy catalogs cover the first layer and miss the second entirely because they require a deeper understanding of the product information relationship to potential customers.
Core specs are the measurable, structured product attributes that describe a product's features. For apparel that is fabric composition, weight, fit, sleeve length, neck size, length, country of origin. For electronics it is screen size, memory, resolution, refresh rate, port count, voltage. For food and beverage it is allergens, ingredients, weight, dietary tags. These attributes get extracted from product text, manufacturer pages, and increasingly from images of the product or the packaging itself.
Contextual attributes describe situation and use rather than physical specification. Party wear, beach-friendly, summer casual, work-from-home, dewy finish, gift-ready, vegan, eco-friendly. Supplier feeds almost never contain these, which is why most legacy catalogs cannot filter on them. Customer behavioral data and SEO understanding is what unlocks this layer: being able to reason about how the product will be used based on visual style, language patterns in adjacent listings, and behavioral signals from shoppers who searched and filtered allows you to define these hyper personalized values.
A general merchandise retailer carrying both electronics and clothing has to manage two completely different attribute spaces. Electronics need screen type, memory capacity, resolution, and special features. Clothing needs top type, bottom type, footwear category, fit, fabric, and care instructions. No single static schema covers both well, which is why category-aware enrichment matters. The schema has to know which attributes apply to which category before the engine generates anything, and the enrichment pipeline has to enforce that mapping during generation.
While the above attribute enrichment work focuses on creating accurate attributes that don’t exist, an area of attribute enrichment that goes under the radar is the optimization of existing attributes. You see this work focus in a few areas:
Clean, structured attributes are the foundation every other catalog optimization task sits on. Things like schema markup, marketplace feeds, faceted navigation, search index, and taxonomy structure depend on the right attributes being captured in the right fields with the right values. When attributes are messy, missing, poorly structured, or buried as free text inside a description your searchability is greatly affected.
The first place structured product data pays off is in search and discovery. Buyers filter by size, color, material, voltage, certification, and dozens of other category-specific facets. Each filter combination, built on product attributes, is a long-tail buyer query waiting to convert. A product with relevant attributes like material: linen, length: midi, color: navy, and sustainability: GOTS certified populated cleanly ranks for every combination of those terms, powering product discovery and power discovery across channels as customers discover the right items, surfaces on every filter a shopper applies, matches shopper queries.
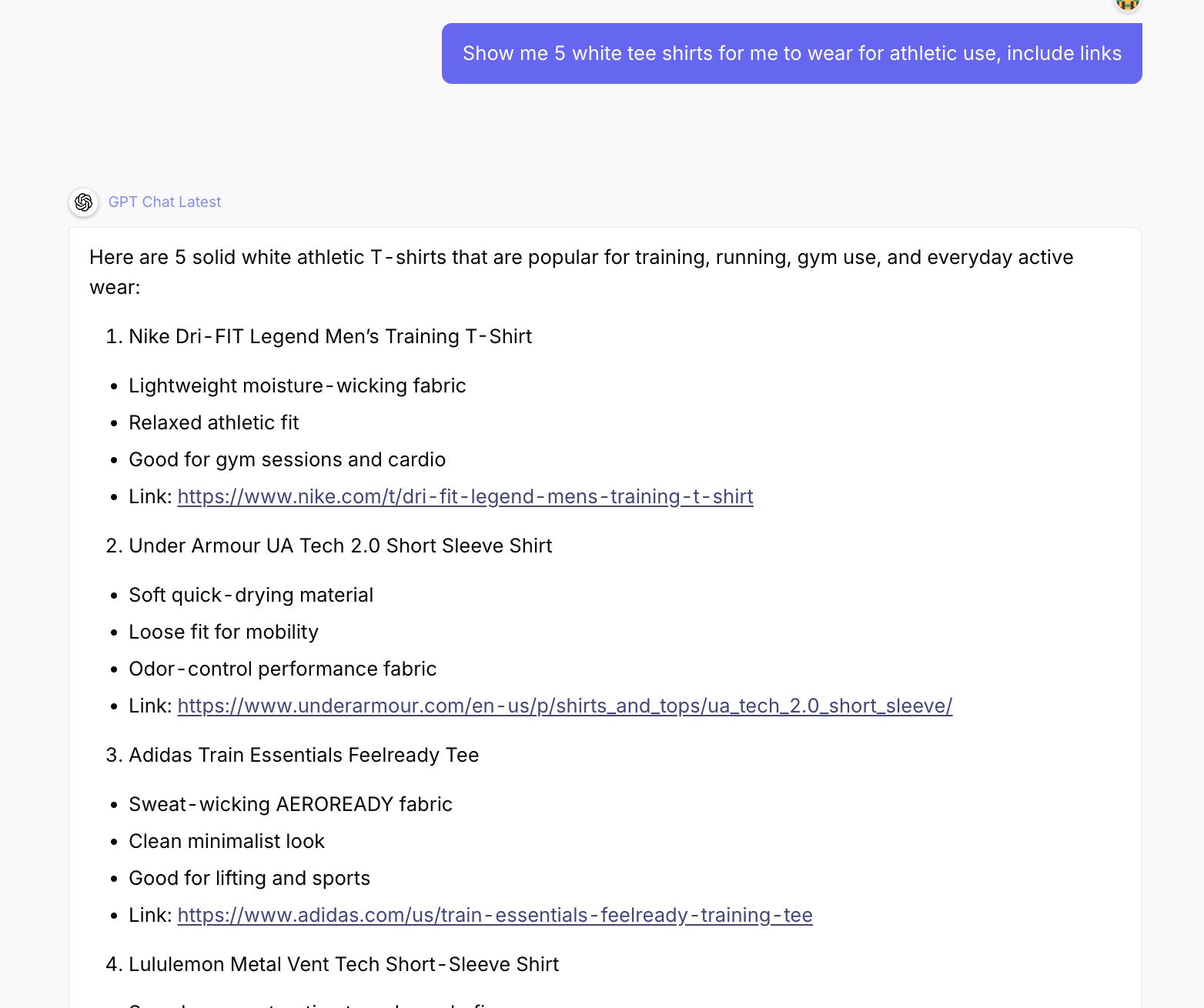
Google AI Mode, ChatGPT, Perplexity, and Vertex AI Search results and other ai systems are becoming primary product discovery channels, and they match listings to shopper queries on structured data completeness and structure, not on keyword density. Sparse or duplicate product listings without structured data simply do not surface in those experiences. Enriched, standardized, accurate product listings (or enriched listings) are what these systems can interpret and cite as canonical product information. Brands that enrich early build a structural advantage in search ranking and competitive edge with search engines and the channels that will deliver most of the next decade's discovery traffic.
Baymard's 2025 cart-abandonment data shows roughly 70% of online shoppers abandon carts due to incomplete or unclear product information. Enriched attributes are the direct counter. Accurate dimensions, materials, fit detail, and care instructions give shoppers the confidence to commit, reduce returns (the product they receive matches what they ordered), and lift average order value through better-matched recommendations that improve customer experience. Enrichment is one of the few catalog programs that hits revenue, returns, customer experience, and operational efficiency at the same time.
The case for doing manual attribute enrichment is the SEO and conversion lift covered above. The case for automating it is the cost, speed, accuracy, and consistency math that manual tagging cannot match. The same enriched catalog produced by a human team versus an AI pipeline differs on four economic axes that compound as the catalog grows.
Manual attribute tagging is one of the most expensive jobs in catalog operations. A merchandiser running an attribute audit on a single category spends hours moving between supplier spreadsheets, product images, PIM screens, and validation tooling. Multiply that by every new SKU, every vendor change, and every seasonal refresh and the cost is full-time headcount per category. Automated enrichment frees merchandising teams from spreadsheet management and reroutes their time toward higher-value strategic work like assortment planning, brand positioning, and customer experience improvements that AI cannot do.
The slowest step in launching a new SKU or onboarding a new vendor is rarely the merchandising decision itself. It is the manual attribute tagging that has to happen before the product can publish to the storefront and the marketplace feeds. AI-driven enrichment can reduce product onboarding time by up to 50% on new vendor and new collection launches, which is the kind of cycle-time saving that compounds across every drop. Faster onboarding also unlocks faster revenue: a SKU that sits in the queue for a week is a SKU that is not selling.
MIT research benchmarks human data tagging at an average error rate of 3.5%. That is the floor for what manual remediation can achieve, and it is the bar AI-driven enrichment has to clear. Modern enrichment pipelines hit that bar when configured with category-aware schemas, controlled value lists, and the validation-and-retry loop covered later in this guide. The result is fewer typos, fewer mislabeled SKUs, and fewer wrong attribute values flowing into the product catalog and downstream channels.
Manual tagging produces inconsistency by default because different merchandisers make different judgment calls on the same attribute. Color "navy" gets entered as "Navy," "navy blue," "dark blue," and "indigo" depending on who is tagging. Automated enrichment with a controlled value list produces the same attribute, formatted the same way, with the same value on every SKU across the storefront, marketplaces, ad feeds, and recommendation models. Standardization is the precondition for clean faceted navigation, clean product schema, and clean channel feeds. Manual tagging undermines all three.

Most of the day-to-day catalog problems ecommerce retailers and B2B sellers complain about reduce to attribute problems. Enrichment is what fixes them at scale.
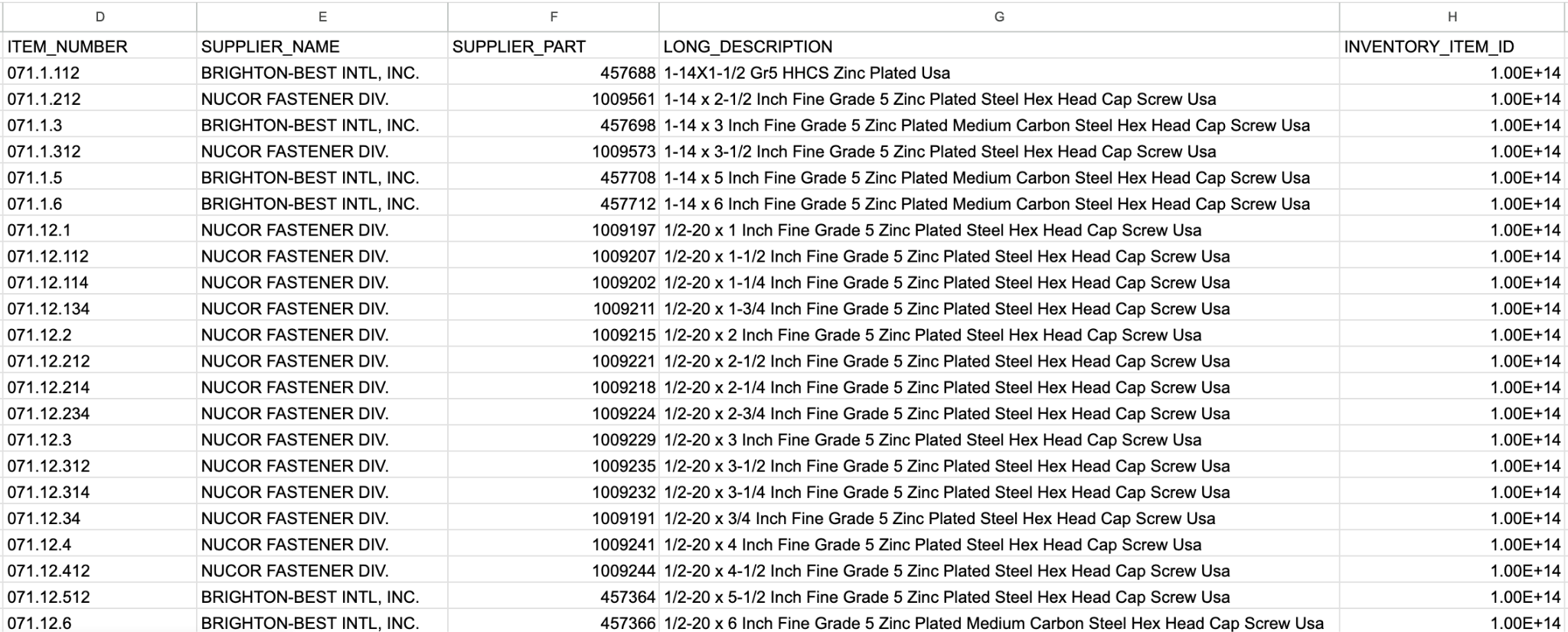
Product data arrives from supplier spreadsheets, ERPs, flat files, PIMs like Akeneo, and PDF catalogs. Completeness and standardization vary significantly between vendors and product categories. The same conceptual attribute is named differently, formatted differently, or missing entirely across product lines. Enrichment standardizes the vocabulary so every SKU describes itself in the same terms regardless of the source.
Modern PIM systems detect when product data is missing, inconsistent, or inaccurate. Fixing that data at scale is a separate problem. Allocating humans to manually correct missing attributes is expensive, slow, and itself error-prone. Manual remediation introduces a meaningful new layer of mistakes on top of the ones it tries to fix, which is why AI-powered enrichment scales where manual processes cannot.
B2B ecommerce catalogs frequently run into the millions of SKUs, often with numerical attribute data like measurements, voltages, and part numbers. When that data is inaccurate or missing, the cost is severe for both the seller and the customer whose operations depend on receiving the right part on time. Manual remediation at that scale is not realistic for ecommerce teams, which makes AI-driven enrichment the only practical option.
Supplier feeds give you specs. They do not give you trend tags and market trends like party wear, beach-friendly, winter essential, dewy finish, or eco-friendly. Those attributes are what modern shoppers search and filter on, and they shift constantly. Multimodal enrichment combined with behavioral data can generate these contextual tags and update them as trends move, which a static PIM schema cannot do.
Amazon, Walmart, eBay, Google Shopping, Pinterest, and other ecommerce platforms all expect product data in their own format with their own required fields. Feed-management platforms handle validation, normalization, and channel-specific formatting that prevent bad data from publishing. Built-in alerting, hard stops, inventory buffers, and random sampling are all part of the validation layer that sits between enriched data and the live channel.

Enriched attributes are only valuable when they are activated downstream. The same attribute data feeds multiple channels and every program that depends on knowing what a product actually is.
Push enriched attributes into the search and browse indexes immediately to improve search relevance. Configure faceted navigation filters across specific categories around the high-value enriched attributes (color, size, material, brand, contextual tags). Every filter is a long-tail query waiting to match shopper intent, and every match is a conversion path.
Product schema (price, availability, brand, color, size, aggregateRating) only generates rich snippets when the underlying attributes are structured, not parsed out of free-form copy. Rich snippets give listings disproportionately more SERP real estate, which translates into higher click-through rates on every keyword the page already ranks for.
Recommendation models perform proportional to the data they have, and how well they understand it. Detailed attributes power product similarity, lookalike sets, complementary product suggestions, and personalized shopping experiences. Searchandising rules can be tuned around attribute values: boost lightweight summer items in May, surface party wear in December, prioritize work-from-home essentials on a Monday morning.
Meta and TikTok dynamic product ads use catalog attribute data to populate ad creative. Enriched attributes mean accurate ad creative; sparse attributes mean generic ad creative that converts worse. Channel-specific feeds (Google Shopping, Pinterest Rich Pins, Instagram Shopping) all draw from the same enriched attribute base.
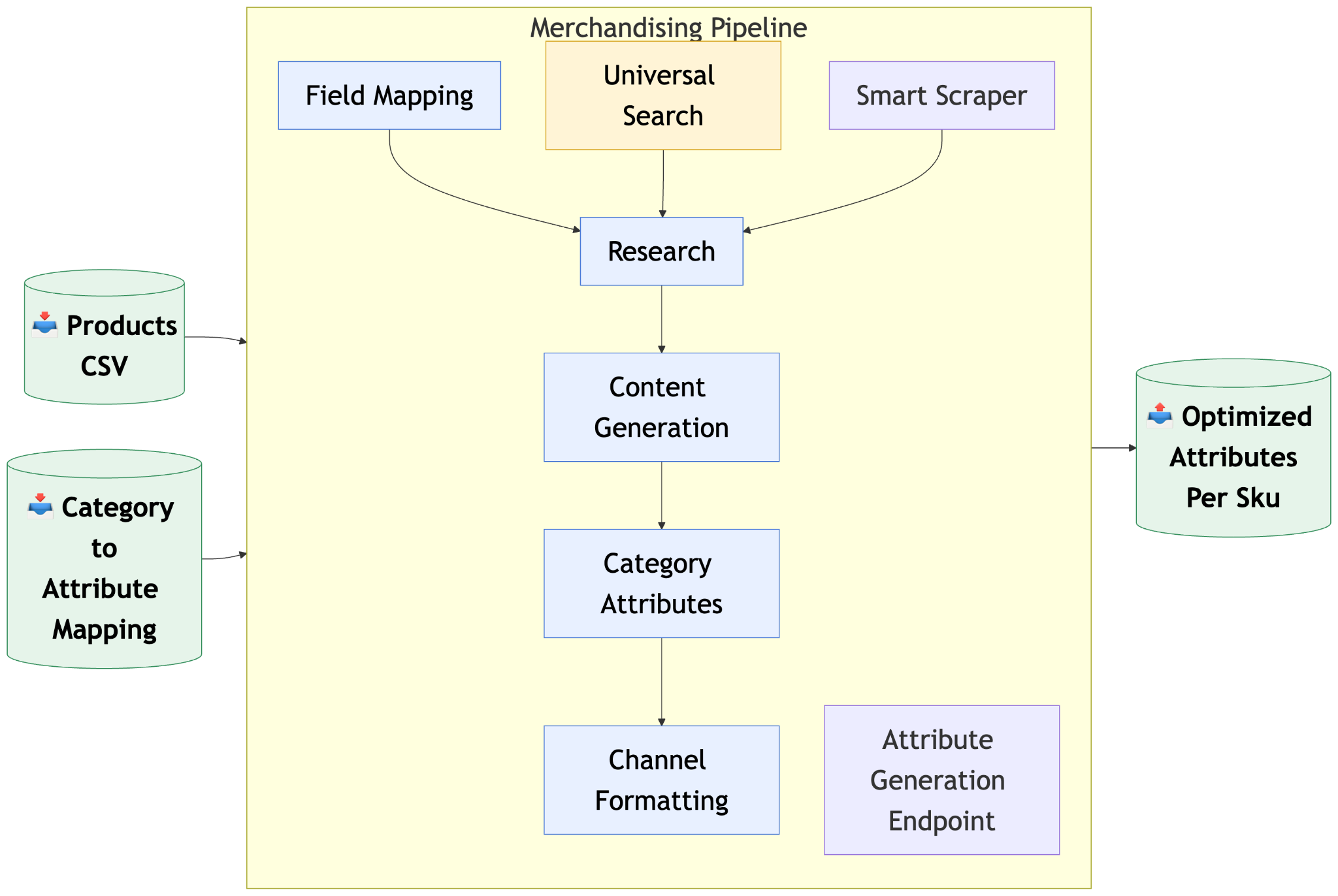
All the enrichment best practices above add up to real work when a catalog runs into the thousands or millions of SKUs and most existing attribute fields started life empty or inconsistent. Pumice.ai automates the entire SKU onboarding workflow through our Merchandising Pipeline, with attribute enrichment handled by specific Ai endpoints that learn your product data, your catalog schema, and your attribute structure. Go from sparse vendor flat file to fully enriched product data grounded in real, verifiable data from 1st party sources.
The workflow runs in three steps that apply to every Pumice endpoint - including generate_attributes. Step 1 is the research phase that gathers and validates source data. Step 2 is the generation phase where rules, examples, validation, and the retry loop produce the structured attribute output. Step 3 is the human-in-the-loop review and export back into the catalog system.
The research phase focuses on augmenting the product data the brand has for each SKU with verified information from trusted sources. The goal is to enrich the available information so the attribute generator has real facts to extract from, without allowing the model to hallucinate specs that do not exist on the product.
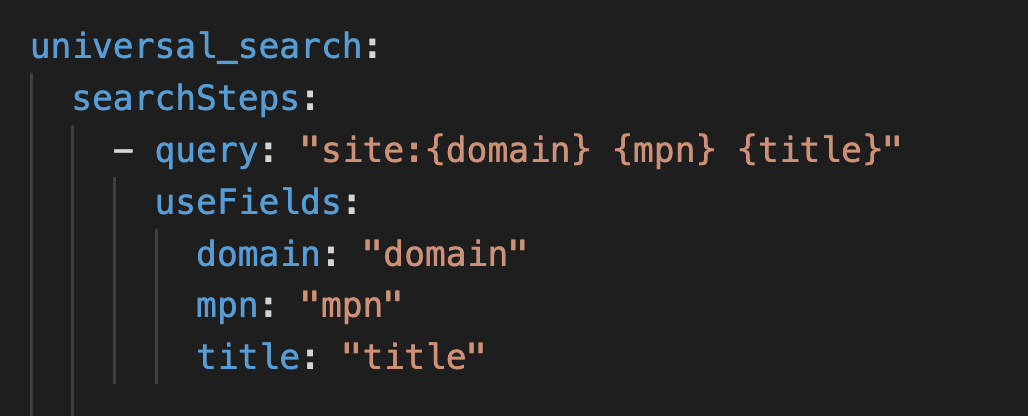
The Pumice research phase is fully configurable per run through a YAML configuration file. You define which search steps to run, the order they run in, and which fields from the CSV row get filled into each search query. A typical first query is a tight site search like site:manufacturer.com plus the SKU and product title, and the placeholders for domain, MPN, and title pull from the matching columns in your CSV row.
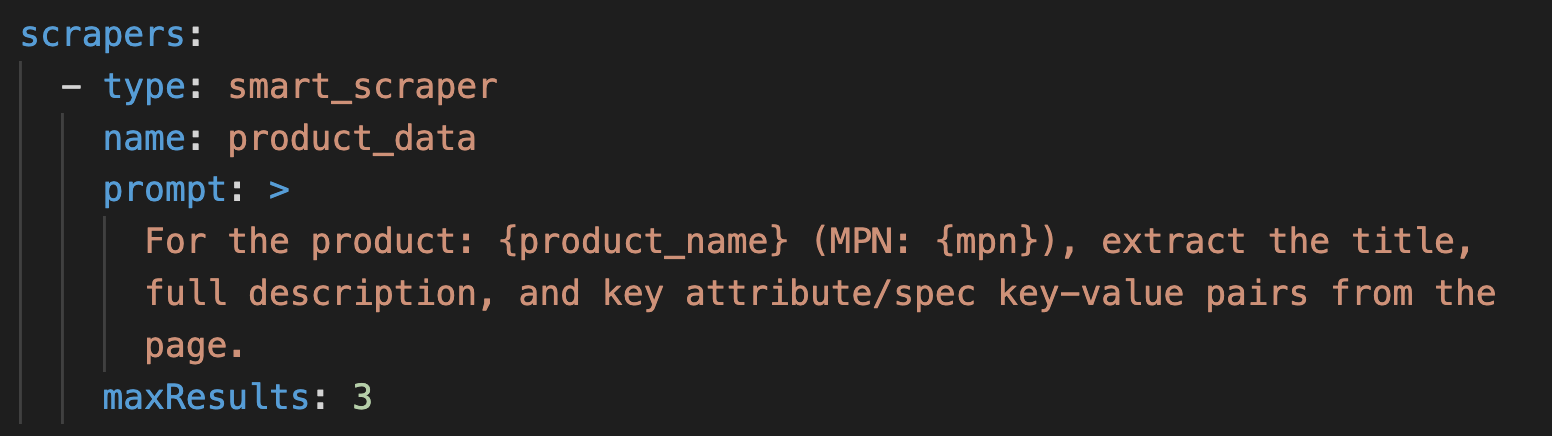
The smart_scraper accepts a custom text prompt that tells it exactly what to extract from each page. For attribute enrichment, the prompt focuses on the spec table, the technical attributes section, the materials list, the certifications, and any structured key-value pairs the source page exposes.
For catalogs that came with manufacturer PDF catalogs, spec sheets, or vendor line sheets, the research phase can use the PDF alongside the web scraper for additional grounded data. Pumice breaks the product catalog data into a readable format, extracts the structured attribute data, and feeds it into the generation step. A focus block in the configuration lets you tell the generator which source to trust when sources disagree, with options for webscrape, domain, and pdf_catalog.
Once the research phase finds relevant source pages, the system automatically runs a validation check against the original CSV row. The check confirms the scraped page is the same product before any data flows into generation. Without it, ai models could enrich a product with attributes from a different variant or a different SKU, which is how catalogs end up with wrong voltages, wrong sizes, or wrong materials baked in across thousands of listings. This is a critical issue with using ChatGPT/Claude to enrich your product data that Pumice solves. Everything is verifiable and validated (real product that ChatGPT hallucinates!).
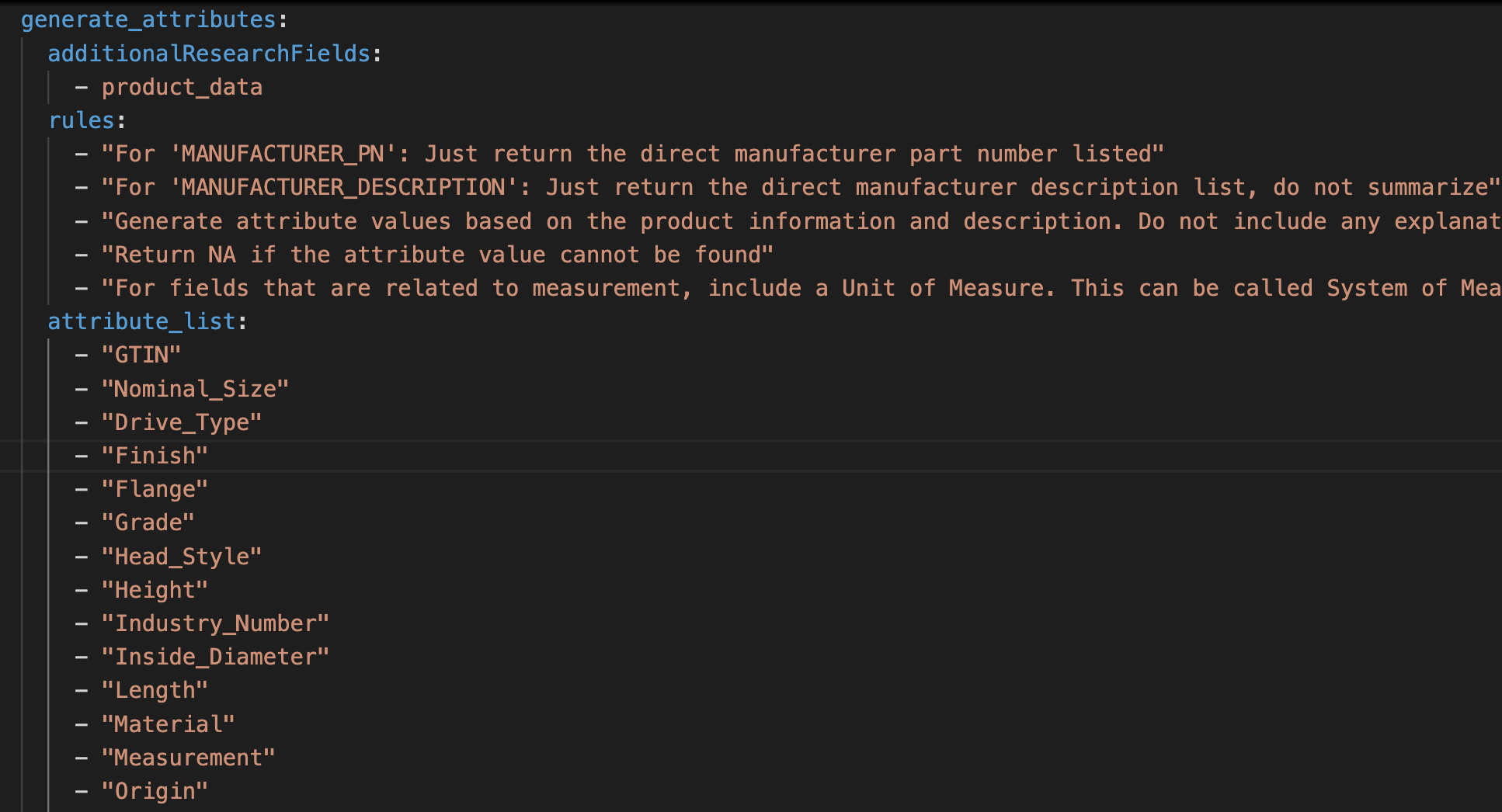
After the research phase delivers validated source data, the generate_attributes endpoint produces the structured attribute set for the SKU. The system can generate attributes for thousands of products per run. The endpoint receives the validated research data, the existing catalog data, the rules you define, the examples you provide, and the validation thresholds you set.
You have two ways to control which attributes the endpoint generates. The first is to provide an explicit list of attribute keys in the configuration file with rules for each one. Tell the endpoint to populate brand, model, voltage, color, weight, certifications, and any other keys you require, and the endpoint will work to populate exactly those fields on every SKU. The second is to leave the key list off and let the model decide what attribute keys and values make the most sense given the product data. The second mode is useful for exploratory enrichment on new categories or when you want the model to surface attributes you might not have thought to require.
For catalogs that span multiple categories with different attribute spaces, Pumice supports a category-to-attribute mapping file that you upload through the dashboard. The mapping defines which attribute keys apply per category, so the endpoint generates only the relevant attributes for each SKU based on its category assignment. Electronics SKUs get screen size, memory, resolution, and ports. Clothing SKUs get fabric composition, fit, sleeve length, and care instructions. The same pipeline handles every category without you writing per-category code.
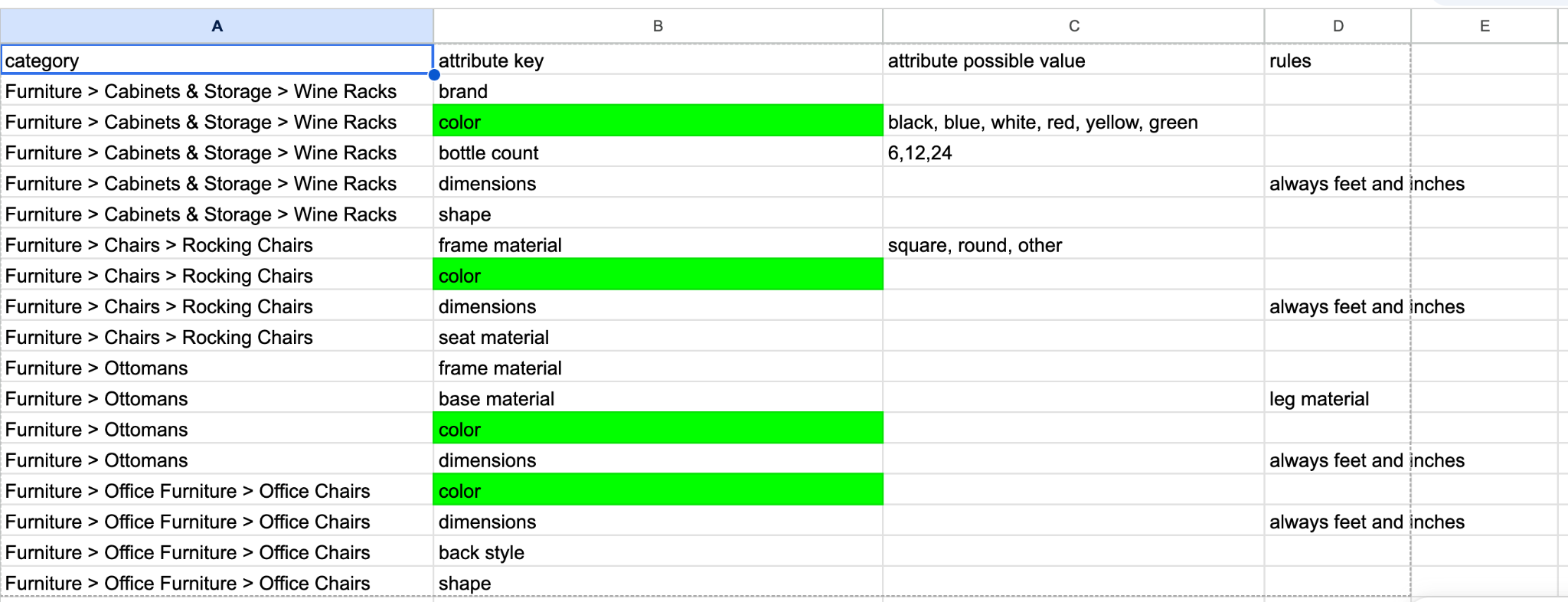
The mapping file also supports optional fields per attribute key. A possible values list constrains the model to a controlled vocabulary (color must be one of navy, black, white, charcoal, taupe). Attribute-key-specific rules let you enforce category-specific instructions (fabric composition must be expressed as percentages summing to 100, voltage must include the unit). These optional fields are where most of the data-quality control happens, because they make the endpoint produce values that fit your schema instead of free-form text the downstream channels reject.
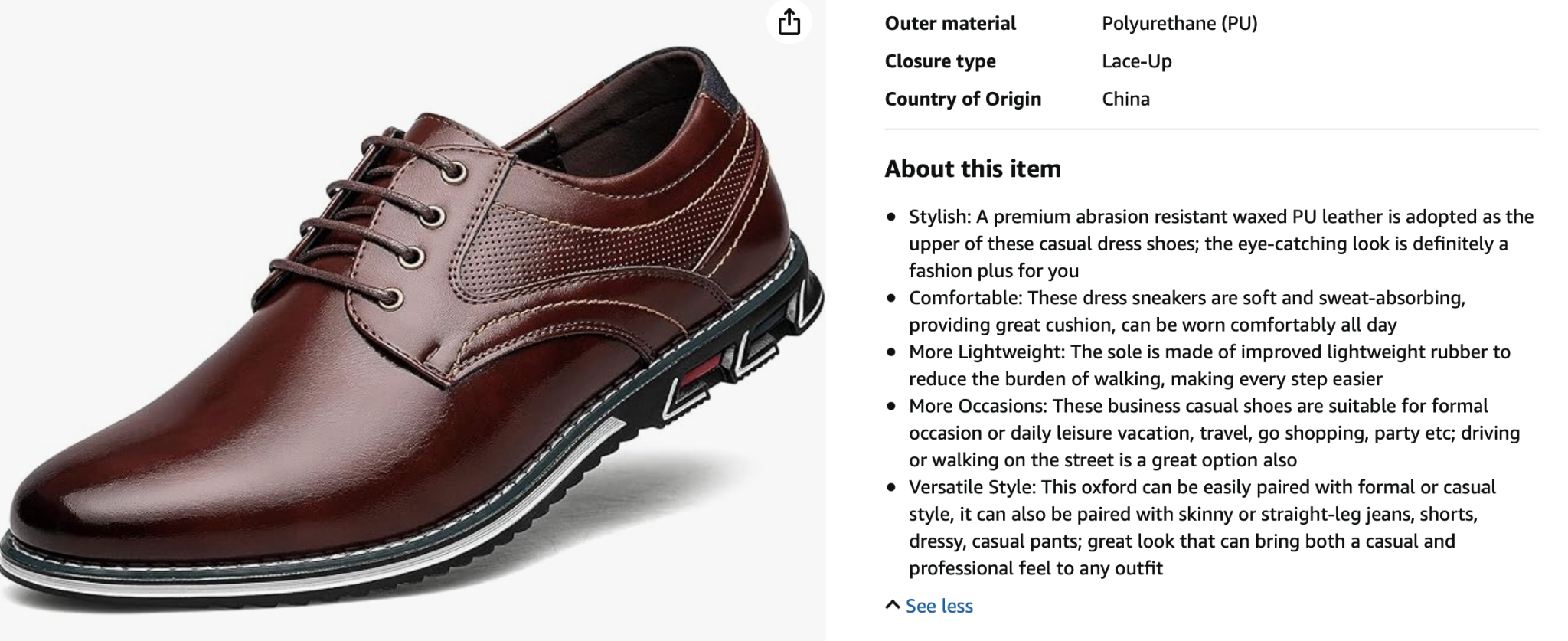
The generate_attributes endpoint is multimodal. It can use product text data and product images together to extract attributes. The image input is what unlocks reliable extraction of visual attributes (color, pattern, material finish, style) and context attributes (lightweight, casual, formal) that text alone often misses. Brands in fashion retail and other categories with strong customer intent signals and product photography see noticeably higher attribute completeness because the visual input fills the gaps the supplier description left behind.
Rules are plain language instructions that tell the model how to produce attributes for your catalog. Examples include rules like always populate color, brand, and size; express fabric composition as percentages; never invent certifications that do not appear in source data; use the value Unknown rather than leaving a required field blank. Examples are sample SKUs with their fully-populated attribute sets so the model can see what good output looks like for your catalog. A handful of category-specific examples plus a tight rules list almost always outperforms a long generic rule list.
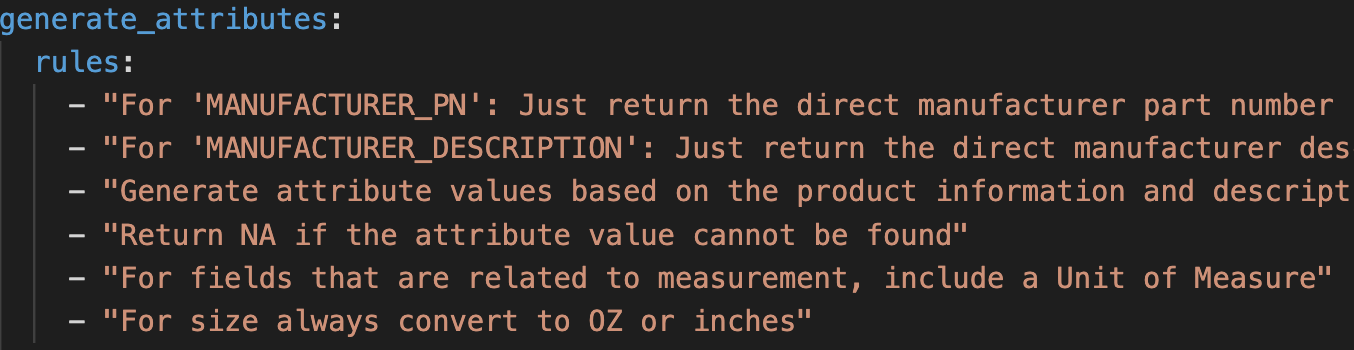
Validation runs after the attributes are generated and enforces hard rules the model must obey. Things like: required fields must be populated, values must come from the possible values list, numerical attributes must match the expected unit format. If a candidate output fails validation, the pipeline retries with additional structure to ensure your final generated data fits the format.
Generated attributes surface in the Pumice dashboard for merchandiser review. Every suggested attribute is visible alongside the source data the engine used to produce it, so reviewers can see exactly why the model proposed each value. Approve, refine, or reject each attribute. Approved attributes export to CSV (or push through API integration) and load back into your PIM. The rejection signal feeds back into model refinement so the next run on the same category surfaces fewer false positives.
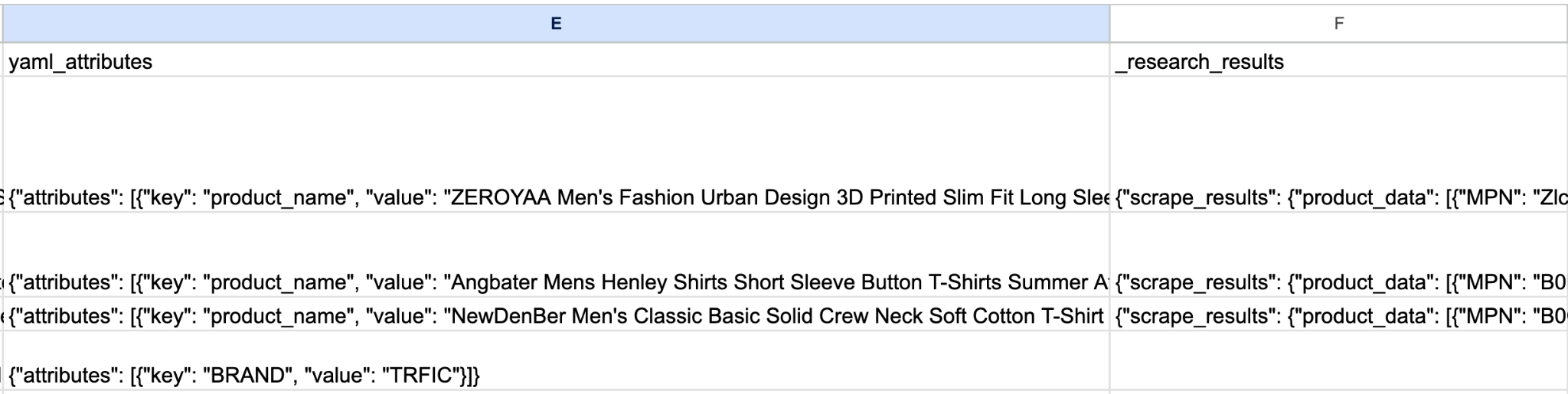
A concrete example makes the workflow tangible. For this walkthrough the starting SKU is a high powered flashlight. The CSV row carries only a one-line title, a manufacturer code, an ERP description column, and the manufacturers website. The catalog needs the full attribute set populated before the product can be added to our site. Technical products like this need quality attributes for the buyer to ensure they are purchasing the correct product.

The configuration loads a category-to-attribute mapping file that defines the attribute schema: lumens, dimensions, modes, battery type, material. I kept the rules simple by putting them as general rules in the configuration file, not the mapping file: to use inches, list all modes, and all materials.
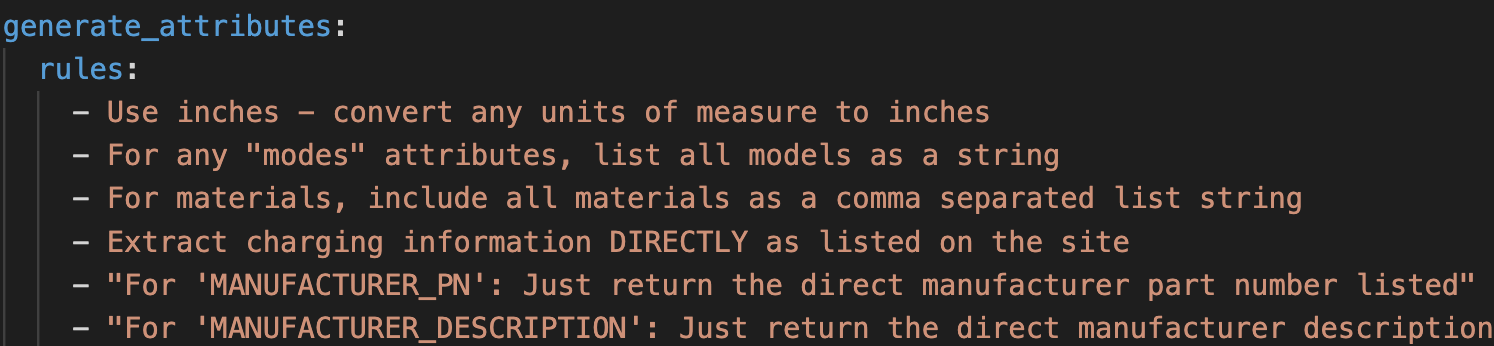
The smart_scraper prompt is generalized to extract all attributes and specs from any webpage. We keep this general so it works for all use cases and categories.
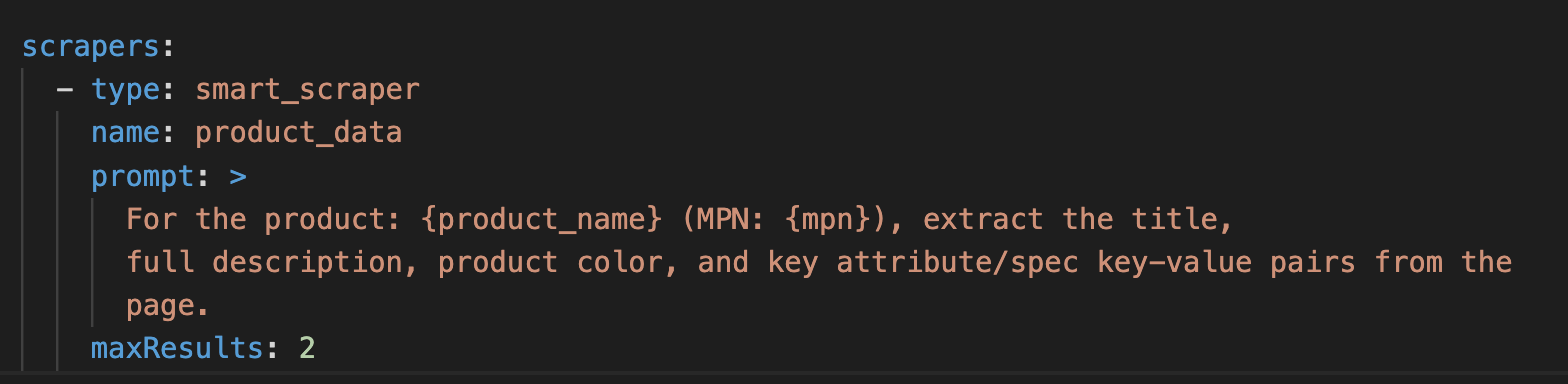
Step 1 runs the narrow site search against the brand domain, lands on the brand PDP, and validates the scraped SKU matches the CSV row. The scraper extracts all attributes and specs. Three product images from the PDP are also found: a flat lay shot, a model lifestyle shot, and a product box shot.
Step 2 runs the generate_attributes endpoint. The model uses the scraped text plus the three images to populate the schema.
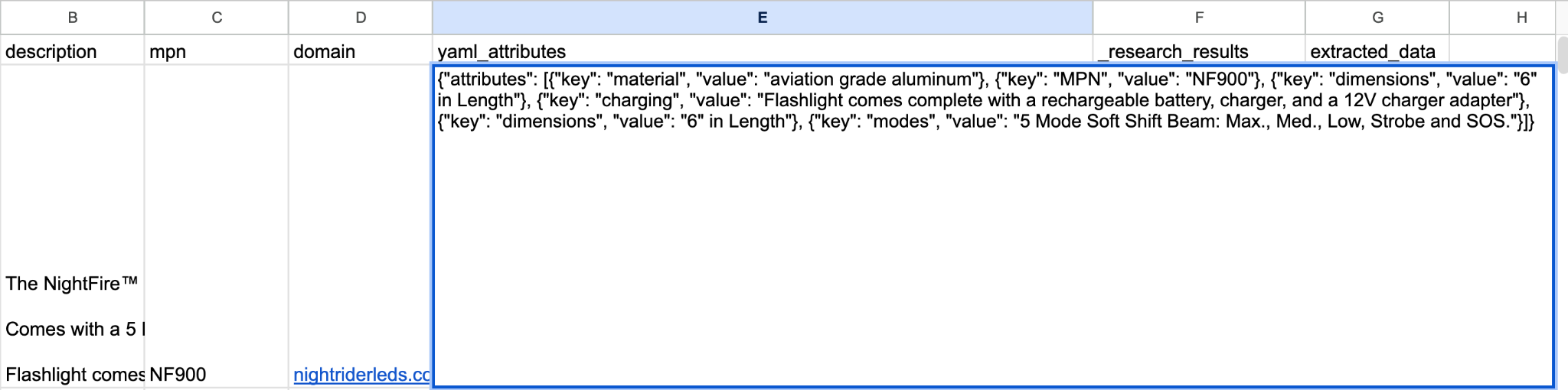
Results come back in the yaml_attributes field, with _research_results showing the exact PDP where the data came from. Fields “modes” and “charging” are listed exactly as seen on the original PDP that was found.

Product attribute enrichment is the catalog program that quietly enables every other catalog program. Faceted navigation, search relevance, product schema, recommendations, AI shopping surfaces, dynamic ads, marketplaces, and personalization all run on the same underlying attribute data. Product data determines the outcome (and the key benefits of strong attribute management), get the attributes right and every downstream program performs better. Get them wrong and every downstream program is fighting uphill.
The next step in the product data enrichment process is a focused 30-day plan: audit attribute coverage per category, define the category-to-attribute mapping and possible values list for the top three categories by revenue, run Pumice across one category as a pilot, walk the dashboard review with the merchandising team, and export the approved attribute set into the PIM. Measure attribute coverage, faceted search conversion, and product-onboarding time at day 30, day 60, and day 90.
Pumice.ai runs the full catalog enrichment workflow described in this article: catalog ingest, multimodal research, attribute generation against your category-specific schema, and validation back into your PIM. Free to try, no credit card required. Bring a CSV of SKUs and see how the generate_attributes endpoint fills the gaps your supplier feeds left behind. Sign up today: https://www.pumice.ai/contact-us
